Россия, Махачкала


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Был в сети 19.12.2022 11:01

Садыков Магомедгусейн Ахмедович
Учитель информатики и ИКТ
32 года
Местоположение
Специализация
Оценка количественных параметров текстовых документов
Категория:
Информатика
06.05.2019 12:55

Просмотр содержимого документа
«Оценка количественных параметров текстовых документов»

ОЦЕНКА КОЛИЧЕСТВЕННЫХ ПАРАМЕТРОВ ТЕКСТОВЫХ ДОКУМЕНТОВ
ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ

Ключевые слова
- кодовая таблица
- восьмиразрядный двоичный код
- информационный объём текста
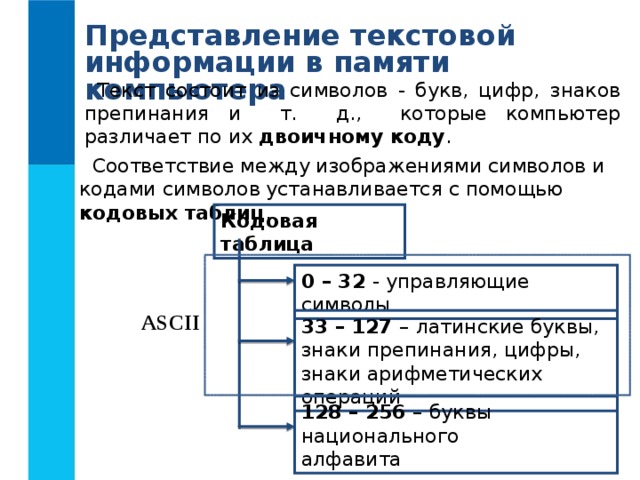
Представление текстовой информации в памяти компьютера
Текст состоит из символов - букв, цифр, знаков препинания и т. д., которые компьютер различает по их двоичному коду .
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых таблиц .
Кодовая таблица
0 – 32 - управляющие символы
ASCII
33 – 127 – латинские буквы, знаки препинания, цифры, знаки арифметических операций
128 – 256 – буквы национального
алфавита
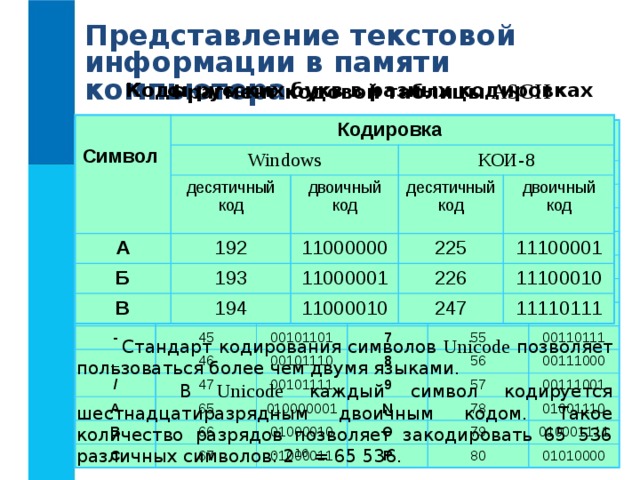
Представление текстовой информации в памяти компьютера
Коды русских букв в разных кодировках
Фрагмент кодовой таблицы ASCII
Символ
Кодировка
Windows
десятичный код
А
КОИ-8
Б
192
двоичный код
193
десятичный код
В
11000000
11000001
194
двоичный код
225
226
11100001
11000010
247
11100010
11110111
Символ
Десятичный код
Пробел
32
!
Двоичный код
Символ
33
#
00100000
0
35
00100001
$
Десятичный код
48
Двоичный код
00100011
36
*
1
2
00110000
42
=
49
00100100
,
43
00110001
00101010
3
50
44
4
00110010
00101011
51
-
5
_
00101100
00110011
52
45
00110100
46
6
53
00101101
/
54
00101110
A
7
47
00110101
8
65
00110110
B
55
00101111
00110111
56
9
C
010000001
66
00111000
67
N
57
01000010
O
78
00111001
01000011
P
01001110
79
80
010001111
01010000
Соответствие между изображениями символов и кодами символов устанавливается с помощью кодовых таблиц .
Стандарт кодирования символов Unicode позволяет пользоваться более чем двумя языками.
В Unicode каждый символ кодируется шестнадцатиразрядным двоичным кодом. Такое количество разрядов позволяет закодировать 65 536 различных символов: 2 16 = 65 536.

Информационный объём фрагмента текста
I - информационный объём сообщения
K – количество символов
i – информационный вес символа
I = K i
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
- 8 битов (1 байт) - восьмиразрядная кодировка ;
- 6 битов (2 байта) - шестнадцатиразрядная кодировка .
Информационный объём фрагмента текста - это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования.

Информационный объём фрагмента текста
Задача 1. Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Жан-Жака Руссо:
Тысячи путей ведут к заблуждению, к истине - только один.
Решение
В данном тексте 57 символов (с учётом знаков препинания и пробелов). Каждый символ кодируется одним байтом. Следовательно, информационный объём всего текста - 57 байтов.
Ответ: 57 байтов.

Информационный объём фрагмента текста
Задача 2. В кодировке Unicode на каждый символ отводится два байта. Определите информационный объём слова из 24 символов в этой кодировке.
Решение.
I = 24 2 = 48 (байтов).
Ответ: 48 байтов.

Информационный объём фрагмента текста
Задача 3. Автоматическое устройство осуществило перекодировку информационного сообщения на русском языке, первоначально записанного в 8-битовом коде, в 16-битовую кодировку Unicode . При этом информационное сообщение увеличилось на 2048 байтов. Каков был информационный объём сообщения до перекодировки?
Решение
Информационный вес каждого символа в 16-битовой кодировке в два раза больше информационного веса символа в 8-битовой кодировке. Поэтому при перекодировании исходного блока информации из 8-битовой кодировки в 16-битовую его информационный объём должен был увеличиться вдвое, другими словами, на величину, равную исходному информационному объёму. Следовательно, информационный объём сообщения до перекодировки составлял 2048 байтов = 2 Кб.
Ответ: 2 Кбайта.

Информационный объём фрагмента текста
Задача 4. Выразите в мегабайтах объём текстовой информации в «Современном словаре иностранных слов» из 740 страниц, если на одной странице размещается в среднем 60 строк по 80 символов (включая пробелы). Считайте, что при записи использовался алфавит мощностью 256 символов.
Решение
K = 740 80 60
N = 256
I - ?
I = K i
N = 2 i
256 = 2 i = 2 8 , i = 8
К = 740 80 60 8 = 28 416 000 бит = 3 552 000 байтов =
= 3 468,75 Кбайт 3,39 Мбайт.
Ответ: 3,39 Мбайт.

Самое главное
Текст состоит из символов - букв, цифр, знаков препинания и т. д., которые человек различает по начертанию. Компьютер различает вводимые символы по их двоичному коду. Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц .
В зависимости от разрядности используемой кодировки информационный вес символа текста, создаваемого на компьютере, может быть равен:
- 8 битов (1 байт) - восьмиразрядная кодировка ;
- 6 битов (2 байта) - шестнадцатиразрядная кодировка .
Информационный объём фрагмента текста - это количество битов, байтов (килобайтов, мегабайтов), необходимых для записи фрагмента оговорённым способом кодирования .
Вопросы и задания
Сообщение занимает 6 страниц по 40 строк, в каждой строке записано по 60 символов. Информационный объём всего сообщения равен 28800 байтам. Сколько двоичных разрядов было использовано на кодирование одного символа?
В какой кодировочной таблице можно закодировать 65 536 различных символов?
- ASCII
- Windows
- КОИ-8
- Unicode
В кодировке ASCII каждый символ кодируется 8 битами. Определите информационный объём сообщения в этой кодировке:
Длина данного текста 32 символа.
- 32 бита
- 320 битов
- 32 байта
- 256 байтов
Почему кодировки, в которых каждый символ кодируется цепочкой из восьми нулей и единиц, называются иначе однобайтовыми?
В текстовом режиме экран монитора компьютера обычно разбивается на 25 строк по 80 символов в строке. Определите объём текста, занимающего весь экран монитора, в кодировке Unicode .
Считая, что каждый символ кодируется одним байтом, определите, чему равен информационный объём следующего высказывания Алексея Толстого:
С какой целью была введена кодировка Unicode?
Не ошибается тот, кто ничего не делает, хотя это и есть его основная ошибка.
- 512 битов
- 608 битов
- 8 Кбайт
- 123 байта
Считая, что каждый символ кодируется 16 битами, оцените информационный объем следующей фразы А. С. Пушкина в кодировке Unicode:
Привычка свыше нам дана: Замена счастию она.
- 44 бита
- 704 бита
- 44 байта
- 704 байта
Сообщение, информационный объём которого равен 5 Кбайт, занимает 4 страницы по 32 строки, в каждой из которых записано по 40 символов. Сколько символов в алфавите языка, на котором записано это сообщение?
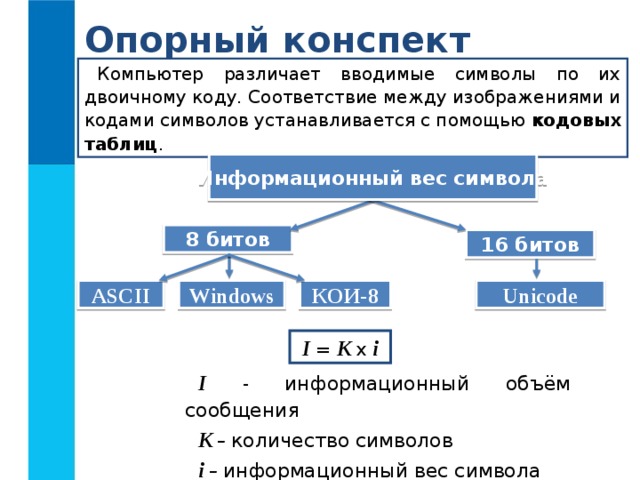
Опорный конспект
Компьютер различает вводимые символы по их двоичному коду. Соответствие между изображениями и кодами символов устанавливается с помощью кодовых таблиц .
Информационный вес символа
8 битов
16 битов
Unicode
ASCII
КОИ-8
Windows
I = K x i
I - информационный объём сообщения
K – количество символов
i – информационный вес символа








© 2019, Садыков Магомедгусейн Ахмедович 1019 3
Рекомендуем курсы ПК и ППК для учителей






Похожие файлы
Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ



