Россия, Буйнакс


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Была в сети 06.06.2022 20:12

Амирханова Асият Каримуллаевна
Учитель математики и информатики
30 лет
Местоположение
Специализация
Тема урока: Кодирование и декодирование информации. Двоичное кодирование информации в компьютере.
Категория:
Информатика
22.02.2022 23:23

Предмет: Информатика.
Преподаватель: Амирханова А. К.
Курс 1.
Специальность: 40.20.01. Право и организации специального обеспечения.
Тема урока: Кодирование и декодирование информации. Двоичное кодирование информации в компьютере.
Кодирование информации
■ Кодирование информации — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
В процессах восприятия, передачи и хранения информации живыми организмами, человеком и техническими устройствами происходит кодирование информации. В этом случае информация, представленная в одной знаковой системе, преобразуется в другую. Каждый символ исходного алфавита представляется конечной последовательностью символов кодового алфавита. Эта результирующая последовательность называется информационным кодом (кодовым словом, или просто кодом).
Примерами кодов являются последовательность букв в тексте, цифр в числе, двоичный компьютерный код и др.
Код состоит из определенного количества знаков (имеет определенную длину), которое называется длиной кода. Например, текстовое сообщение состоит из определенного количества букв, число — из определенного количества цифр.
Преобразование знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы называется перекодированием.
При кодировании один символ исходного сообщения может заменяться одним или несколькими символами нового кода, и наоборот — несколько символов исходного сообщения могут быть заменены одним символом в новом коде. Примером такой замены служат китайские иероглифы, которые обозначают целые слова и понятия.
Кодирование может быть равномерным и неравномерным. При равномерном кодировании все символы заменяются кодами равной длины; при неравномерном кодировании разные символы могут кодироваться кодами разной длины (это затрудняет декодирование). Неравномерный код называют еще кодом переменной длины.
Примером неравномерного кодирования является код азбуки Морзе. Длительное время он использовался для передачи сообщений по телеграфу. Кодовый алфавит включал точку, тире и паузу. При передаче по телеграфу точка означала кратковременный сигнал, тире — сигнал в 3 раза длиннее. Между сигналами букв одного слова делалась пауза длительностью одной точки, между словами — длительностью трех точек, между предложениями — длительностью семи точек.
Вначале код Морзе был создан для букв английского алфавита, цифр и знаков препинания. Принцип этого кода заключался в том, что часто встречающиеся буквы кодировались более простыми сочетаниями точек и тире. Это делало код компактным. Позже код был разработан и для символов других алфавитов, включая русский.
Коды Морзе для некоторых букв.

Чтобы избежать неоднозначности, код Морзе включает также паузы между кодами разных символов.
Декодирование информации
■ Декодирование — обратный процесс восстановления информации из закодированного представления.
В зависимости от системы кодирования информационный код может или не может быть декодирован однозначно. Равномерные коды всегда могут быть декодированы однозначно.
Для однозначного декодирования неравномерного кода важно, имеются ли в нем кодовые слова, которые являются одновременно началом других, более длинных кодовых слов.
Закодированное сообщение можно однозначно декодировать с начала, если выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова.
Закодированное сообщение можно однозначно декодировать с конца, если выполняется обратное условие Фано: никакое кодовое слово не является окончанием другого кодового слова.
Неравномерные коды, для которых выполняется условие Фано, называются префиксными. Префиксный код — такой неравномерный код, в котором ни одно кодовое слово не является началом другого, более длинного слова. В таком случае кодовые слова можно записывать друг за другом без разделительного символа между ними.
Например, код Морзе не является префиксным — для него не выполняется условие Фано. Поэтому в кодовый алфавит Морзе, кроме точки и тире, входит также символ–разделитель — пауза длиной в тире. Без разделителя однозначно декодировать код Морзе в общем случае нельзя.
Предмет: Информатика.
Преподаватель: Амирханова А. К.
Курс 1.
Специальность: 40.20.01. Право и организации специального обеспечения.
Тема урока : Кодирование текстовой информации в компьютере. Кодирование графической информации. Кодирование звуковой информации.
Большую часть информации человек получает с помощью зрения и слуха. Важность этих органов чувств обусловлена развитием человека как биологического вида, поэтому человеческий мозг с большой скоростью способен обрабатывать огромное количество графической и звуковой информации.
С появлением компьютеров возникла огромная потребность научить их обрабатывать такую информацию. Как же такую информацию может обработать компьютер?
Итак, кодирование графической информации осуществляется двумя различными способами: векторным и растровым

|
Программы, работающие с векторной графикой, хранят информацию об объектах, составляющих изображение в виде графических примитивов: прямых линий, дуг окружностей, прямоугольников, закрасок и т.д. Достоинства векторной графики: — Преобразования без искажений. — Маленький графический файл. — Рисовать быстро и просто. — Независимое редактирование частей рисунка. — Высокая точность прорисовки. — Редактор быстро выполняет операции. Недостатки векторной графики: — Векторные изображения выглядят искусственно. — Ограниченность в живописных средствах. |
Программы растровой графики работают с точками экрана (пикселями). Это называется пространственной дискретизацией. |
КОДИРОВАНИЕ РАСТРОВОЙ ГРАФИКИ
Давайте более подробно рассмотрим растровое кодирование информации.
Компьютер запоминает цвет каждой точки, а пользователь из таких точек собирает рисунок.
При этом зная количество пикселей по вертикале и горизонтали, мы сможем найти — разрешающую способность изображения.
Разрешающая способность находится по формуле:
P=n*m,
где n, m — количество пикселей в изображении по вертикали и горизонтали.
В процессе дискретизации каждый пиксель может принимать различные цвета из палитры цветов. При этом зная количество цветов, которые можно использовать в палитре и воспользовавшись формулой Хартли, мы сможем найти количество информации, которое используется для кодирования цвета точки, что мы будем называть глубиной цвета.
N=2i
где N — количество цветов в палитре;
i — глубина цвета.
Таким образом, чтобы найти вес изображения достаточно перемножить разрешающую способность изображения на глубину цвета: L=P*i.
Каким именно образом возможно закодировать пиксель? Для этого используются кодировочные палитры.
КОДИРОВОЧНАЯ ПАЛИТРА RGB
Когда художник рисует картину, цвета он выбирает по своему вкусу. Но цвет в компьютере надо стандартизировать, чтобы его можно было распознать. Поэтому надо определить, что такое каждый цвет.
В экспериментах по производству цветных стекол М. В. Ломоносов показал, что получить любой цвет возможно, используя три различных цвета.

Этот факт был обобщен Германом Грассманом в виде законов аддитивного синтеза цвета.

Давайте рассмотрим два из этих законов:
— Закон трехмерности. С помощью трех независимых цветов можно, смешивая их в однозначно определенной пропорции, выразить любой цвет.
— Закон непрерывности. При непрерывном изменении пропорции, в которой взяты компоненты цветовой смеси, получаемый цвет также меняется непрерывно.
Из биологии вы знаете, что рецепторы человеческого глаза делятся на две группы: палочки и колбочки. Палочки более чувствительны к интенсивности поступаемого света, а колбочки — к длине волны.

Если посмотреть, как распределяется количество колбочек по тому, на какую длину волны они «настроены», то количество колбочек «настроенных» на синий, красный и зеленый цвета окажется больше.

Поэтому такие цвета были взяты основными для построения цветовой модели, которая получила название RGB (Red, Green, Blue). То есть задавая количество любого из этих трех цветов, можно получить любой другой. Для кодирования каждого цвета было выделено 8 бит (режим True-Color). Таким образом, количество каждого цвета может изменяться от 0 до 255, часто это количество выражается в шестнадцатеричной системе счисления (от 0 до FF).
Так как описание цвета происходит определением трех величин, то это наводит на мысль считать их координатами точки в пространстве. Получается, что координаты цветов заполняют куб.

При этом яркость цвета определяется тем насколько близка к максимальному значению хотя бы одна координата из трех.
Поскольку именно модель RGB соответствовала основному механизму формирования цветного изображения на экране, большинство графических файлов хранят изображение именно в этой кодировке. Если же используется другая модель, например в JPEG , то приходится при выводе информации на экран преобразовывать данные.
КОДИРОВАНИЕ ЗВУКОВОЙ ИНФОРМАЦИИ
Давайте перейдем к кодированию звуковой информации.
Из курса физики вам всем известно, что звук — это непрерывная волна с изменяющейся амплитудой и частотой.

Для того, чтобы компьютер мог обрабатывать непрерывный звуковой сигнал, он должен быть дискретизирован, т. е. превращен в последовательность электрических импульсов (двоичных нулей и единиц).
Для этого звуковая волна разбивается на отдельные временные участки.
Гладкая кривая заменяется последовательностью «ступенек». Каждой «ступеньке» присваивается значение громкости звука. Чем больше количество уровней громкости, тем больше количество информации будет нести значение каждого уровня и более качественным будет звучание. Причем, чем больше будет количество измерений уровня звукового сигнала в единицу времени, тем качественнее будет звучание. Эта характеристика называется частотой дискретизации Данная характеристика измеряется в Гц.
При этом на каждое измерение выделяется одинаковое количество бит. Такая характеристика называется — глубина кодирования.
Таким образом, чтобы подсчитать вес звуковой волны достаточно перемножить частоту дискретизации, глубины кодирования и времени звучания такого звука. При этом, рассматривая современное звучание, количество звуковых волн может быть различное, например, для стереозвука — это 2, а для квадрозвука — 4.

Просмотр содержимого документа
«Тема урока: Кодирование и декодирование информации. Двоичное кодирование информации в компьютере.»
Предмет: Информатика.
Преподаватель: Амирханова А. К.
Курс 1.
Специальность: 40.20.01. Право и организации специального обеспечения.
Тема урока: Кодирование и декодирование информации. Двоичное кодирование информации в компьютере.
Кодирование информации
■ Кодирование информации — процесс преобразования сигнала из формы, удобной для непосредственного использования информации, в форму, удобную для передачи, хранения или автоматической переработки.
В процессах восприятия, передачи и хранения информации живыми организмами, человеком и техническими устройствами происходит кодирование информации. В этом случае информация, представленная в одной знаковой системе, преобразуется в другую. Каждый символ исходного алфавита представляется конечной последовательностью символов кодового алфавита. Эта результирующая последовательность называется информационным кодом (кодовым словом, или просто кодом).
Примерами кодов являются последовательность букв в тексте, цифр в числе, двоичный компьютерный код и др.
Код состоит из определенного количества знаков (имеет определенную длину), которое называется длиной кода. Например, текстовое сообщение состоит из определенного количества букв, число — из определенного количества цифр.
Преобразование знаков или групп знаков одной знаковой системы в знаки или группы знаков другой знаковой системы называется перекодированием.
При кодировании один символ исходного сообщения может заменяться одним или несколькими символами нового кода, и наоборот — несколько символов исходного сообщения могут быть заменены одним символом в новом коде. Примером такой замены служат китайские иероглифы, которые обозначают целые слова и понятия.
Кодирование может быть равномерным и неравномерным. При равномерном кодировании все символы заменяются кодами равной длины; при неравномерном кодировании разные символы могут кодироваться кодами разной длины (это затрудняет декодирование). Неравномерный код называют еще кодом переменной длины.
Примером неравномерного кодирования является код азбуки Морзе. Длительное время он использовался для передачи сообщений по телеграфу. Кодовый алфавит включал точку, тире и паузу. При передаче по телеграфу точка означала кратковременный сигнал, тире — сигнал в 3 раза длиннее. Между сигналами букв одного слова делалась пауза длительностью одной точки, между словами — длительностью трех точек, между предложениями — длительностью семи точек.
Вначале код Морзе был создан для букв английского алфавита, цифр и знаков препинания. Принцип этого кода заключался в том, что часто встречающиеся буквы кодировались более простыми сочетаниями точек и тире. Это делало код компактным. Позже код был разработан и для символов других алфавитов, включая русский.
Коды Морзе для некоторых букв.

Чтобы избежать неоднозначности, код Морзе включает также паузы между кодами разных символов.
Декодирование информации
■ Декодирование — обратный процесс восстановления информации из закодированного представления.
В зависимости от системы кодирования информационный код может или не может быть декодирован однозначно. Равномерные коды всегда могут быть декодированы однозначно.
Для однозначного декодирования неравномерного кода важно, имеются ли в нем кодовые слова, которые являются одновременно началом других, более длинных кодовых слов.
Закодированное сообщение можно однозначно декодировать с начала, если выполняется условие Фано: никакое кодовое слово не является началом другого кодового слова.
Закодированное сообщение можно однозначно декодировать с конца, если выполняется обратное условие Фано: никакое кодовое слово не является окончанием другого кодового слова.
Неравномерные коды, для которых выполняется условие Фано, называются префиксными. Префиксный код — такой неравномерный код, в котором ни одно кодовое слово не является началом другого, более длинного слова. В таком случае кодовые слова можно записывать друг за другом без разделительного символа между ними.
Например, код Морзе не является префиксным — для него не выполняется условие Фано. Поэтому в кодовый алфавит Морзе, кроме точки и тире, входит также символ–разделитель — пауза длиной в тире. Без разделителя однозначно декодировать код Морзе в общем случае нельзя.
Предмет: Информатика.
Преподаватель: Амирханова А. К.
Курс 1.
Специальность: 40.20.01. Право и организации специального обеспечения.
Тема урока : Кодирование текстовой информации в компьютере. Кодирование графической информации. Кодирование звуковой информации.
Большую часть информации человек получает с помощью зрения и слуха. Важность этих органов чувств обусловлена развитием человека как биологического вида, поэтому человеческий мозг с большой скоростью способен обрабатывать огромное количество графической и звуковой информации.
С появлением компьютеров возникла огромная потребность научить их обрабатывать такую информацию. Как же такую информацию может обработать компьютер?
Итак, кодирование графической информации осуществляется двумя различными способами: векторным и растровым
| Программы, работающие с векторной графикой, хранят информацию об объектах, составляющих изображение в виде графических примитивов: прямых линий, дуг окружностей, прямоугольников, закрасок и т.д. Достоинства векторной графики: — Преобразования без искажений. — Маленький графический файл. — Рисовать быстро и просто. — Независимое редактирование частей рисунка. — Высокая точность прорисовки. — Редактор быстро выполняет операции. Недостатки векторной графики: — Векторные изображения выглядят искусственно. — Ограниченность в живописных средствах. | Программы растровой графики работают с точками экрана (пикселями). Это называется пространственной дискретизацией. |
КОДИРОВАНИЕ РАСТРОВОЙ ГРАФИКИ
Давайте более подробно рассмотрим растровое кодирование информации.
Компьютер запоминает цвет каждой точки, а пользователь из таких точек собирает рисунок.
При этом зная количество пикселей по вертикале и горизонтали, мы сможем найти — разрешающую способность изображения.
Разрешающая способность находится по формуле:
P=n*m,
где n, m — количество пикселей в изображении по вертикали и горизонтали.
В процессе дискретизации каждый пиксель может принимать различные цвета из палитры цветов. При этом зная количество цветов, которые можно использовать в палитре и воспользовавшись формулой Хартли, мы сможем найти количество информации, которое используется для кодирования цвета точки, что мы будем называть глубиной цвета.
N=2i
где N — количество цветов в палитре;
i — глубина цвета.
Таким образом, чтобы найти вес изображения достаточно перемножить разрешающую способность изображения на глубину цвета: L=P*i.
Каким именно образом возможно закодировать пиксель? Для этого используются кодировочные палитры.
КОДИРОВОЧНАЯ ПАЛИТРА RGB
Когда художник рисует картину, цвета он выбирает по своему вкусу. Но цвет в компьютере надо стандартизировать, чтобы его можно было распознать. Поэтому надо определить, что такое каждый цвет.
В экспериментах по производству цветных стекол М. В. Ломоносов показал, что получить любой цвет возможно, используя три различных цвета.

Этот факт был обобщен Германом Грассманом в виде законов аддитивного синтеза цвета.

Давайте рассмотрим два из этих законов:
— Закон трехмерности. С помощью трех независимых цветов можно, смешивая их в однозначно определенной пропорции, выразить любой цвет.
— Закон непрерывности. При непрерывном изменении пропорции, в которой взяты компоненты цветовой смеси, получаемый цвет также меняется непрерывно.
Из биологии вы знаете, что рецепторы человеческого глаза делятся на две группы: палочки и колбочки. Палочки более чувствительны к интенсивности поступаемого света, а колбочки — к длине волны.
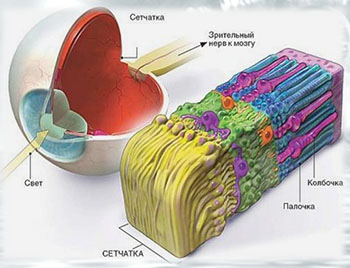
Если посмотреть, как распределяется количество колбочек по тому, на какую длину волны они «настроены», то количество колбочек «настроенных» на синий, красный и зеленый цвета окажется больше.

Поэтому такие цвета были взяты основными для построения цветовой модели, которая получила название RGB (Red, Green, Blue). То есть задавая количество любого из этих трех цветов, можно получить любой другой. Для кодирования каждого цвета было выделено 8 бит (режим True-Color). Таким образом, количество каждого цвета может изменяться от 0 до 255, часто это количество выражается в шестнадцатеричной системе счисления (от 0 до FF).
Так как описание цвета происходит определением трех величин, то это наводит на мысль считать их координатами точки в пространстве. Получается, что координаты цветов заполняют куб.

При этом яркость цвета определяется тем насколько близка к максимальному значению хотя бы одна координата из трех.
Поскольку именно модель RGB соответствовала основному механизму формирования цветного изображения на экране, большинство графических файлов хранят изображение именно в этой кодировке. Если же используется другая модель, например в JPEG , то приходится при выводе информации на экран преобразовывать данные.
КОДИРОВАНИЕ ЗВУКОВОЙ ИНФОРМАЦИИ
Давайте перейдем к кодированию звуковой информации.
Из курса физики вам всем известно, что звук — это непрерывная волна с изменяющейся амплитудой и частотой.

Для того, чтобы компьютер мог обрабатывать непрерывный звуковой сигнал, он должен быть дискретизирован, т. е. превращен в последовательность электрических импульсов (двоичных нулей и единиц).
Для этого звуковая волна разбивается на отдельные временные участки.
Гладкая кривая заменяется последовательностью «ступенек». Каждой «ступеньке» присваивается значение громкости звука. Чем больше количество уровней громкости, тем больше количество информации будет нести значение каждого уровня и более качественным будет звучание. Причем, чем больше будет количество измерений уровня звукового сигнала в единицу времени, тем качественнее будет звучание. Эта характеристика называется частотой дискретизации Данная характеристика измеряется в Гц.
При этом на каждое измерение выделяется одинаковое количество бит. Такая характеристика называется — глубина кодирования.
Таким образом, чтобы подсчитать вес звуковой волны достаточно перемножить частоту дискретизации, глубины кодирования и времени звучания такого звука. При этом, рассматривая современное звучание, количество звуковых волн может быть различное, например, для стереозвука — это 2, а для квадрозвука — 4.









© 2022, Амирханова Асият Каримуллаевна 417 1
Рекомендуем курсы ПК и ППК для учителей






Похожие файлы
Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ


