
Россия, Починки


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Был в сети 20.05.2024 15:13

Хоршев Роман Андреевич
Преподаватель
34 года
Местоположение
Специализация
Практическое занятие №57
Категория:
Информатика
22.11.2023 13:24

Просмотр содержимого документа
«Практическое занятие №57»
Практическое занятие №57 (1И)
Тема: Характеристика основных этапов процесса анализа данных
Цель работы: формирование теоретических и практических навыков работы на языке программирования Python
Оборудование: компьютер с установленной операционной системой Windows, подключение к сети Интернет
Время работы 2 часа
Ход работы
Открываем в браузере colab.google и создаем новый блокнот
Начнём с импорта необходимых библиотек и чтения данных.
Импорт библиотекimport numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
mpl.rcParams.update(mpl.rcParamsDefault)
Загрузка набора данныхЗагружаем файл StudentsPerformance.csv (https://cloud.mail.ru/public/5dJW/uHnh82Huv) в сессионное хранилище
data = pd.read_csv("StudentsPerformance.csv")
Можно использовать функцию df.head в Pandas для просмотра фрейма данных следующим образом:
print(data.head(10))
Вот как должен выглядеть результат результат:
gender race_ethnicity parental_level_of_education lunch \
0 female group B bachelor's degree standard
1 female group C some college standard
2 female group B master's degree standard
3 male group A associate's degree free/reduced
4 male group C some college standard
5 female group B associate's degree standard
6 female group B some college standard
7 male group B some college free/reduced
8 male group D high school free/reduced
9 female group B high school free/reduced
test_preparation_course math_score reading_score writing_score
0 none 72 72 74
1 completed 69 90 88
2 none 90 95 93
3 none 47 57 44
4 none 76 78 75
5 none 71 83 78
6 completed 88 95 92
7 none 40 43 39
8 completed 64 64 67
9 none 38 60 50
Как видим, в прочитанном наборе всего 8 столбцов. Чтобы получить более подробное представление, давайте воспользуемся функцией df.info и узнаем больше о столбцах, с которыми мы имеем дело:
data.info()
Результат:
RangeIndex: 1000 entries, 0 to 999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 gender 1000 non-null object
1 race_ethnicity 1000 non-null object
2 parental_level_of_education 1000 non-null object
3 lunch 1000 non-null object
4 test_preparation_course 1000 non-null object
5 math_score 1000 non-null int64
6 reading_score 1000 non-null int64
7 writing_score 1000 non-null int64
dtypes: int64(3), object(5)
memory usage: 62.6+ KB
Итак, у нас есть три поля типа int, а остальные поля типа object. Приведенная выше информация очень помогает, когда мы применяем различные вычисления на уровне столбца.
Следующим по важности шагом является обнаружение недостающих значений, которые обязаны у нас быть. Если мы это сделаем, то нужно будет соответствующим образом действовать на дальнейших этапах разработки. На этом этапе EDA нам не обязательно иметь дело с пропущенными значениями, но нам нужно понять их, чтобы мы могли побороться с ними позже.
data.isnull().sum()
Результат:
gender 0
race_ethnicity 0
parental_level_of_education 0
lunch 0
test_preparation_course 0
math_score 0
reading_score 0
writing_score 0
dtype: int64
Нам повезло и в нашем наборе данных нет пропущенных значений. Это случается очень нечасто, но когда это случается, то действительно повезло!
Однако, если бы были пропущенные значения, что бы вы сделали? Поступить можно по-разному и либо отбросить отсутствующие значения, если их немного, либо заполнить их средними или медианными значениями с помощью функции Pandas data.fillna().
Одномерный анализТеперь пришло время для быстрой визуализации, чтобы увидеть, какие группы и категории входят в наши данные.
Сначала мы исследуем соотношение мужчин и женщин в наборе данных.
sns.set_style('darkgrid')
sns.countplot(y='gender',data=data,palette='colorblind')
plt.xlabel('Количество')
plt.ylabel('Пол')
plt.show()

График seaborn довольно точно отражает разделение данных на мужчин и женщин. Вот более точная версия подсчета:
female_count = len(data[data['gender']=='female'])
male_count = len(data) - female_count
print("\n Всего женщин:",female_count,"\n","Всего мужчин:",male_count)
Результат:
Всего женщин: 518
Всего мужчин: 482
Теперь давайте посмотрим, как данные делят учащихся на разные расы или этнические группы. Будем следовать той же процедуре, что и на предыдущем шаге. График можно построить с помощью следующего кода:
sns.set_style('whitegrid')
sns.countplot(x='race_ethnicity',data=data,palette='colorblind')
plt.xlabel("Раса/Этнос")
plt.ylabel("Количество")
plt.show()

Затем мы сделаем то же самое, чтобы изучить распределение для 'Уровень образования родителей'. Посмотрим, что у нас там есть.
sns.set_style('whitegrid')
sns.countplot(y='parental_level_of_education',data=data,palette='colorblind')
plt.xlabel('Количество')
plt.ylabel('Раса/Этнос')
plt.show()

Это говорит нам о том, что у большинства родителей есть как минимум степень младшего специалиста.
Двумерный анализДалее мы исследуем, есть ли какая-либо корреляция (зависимость) между отдельными функциями (столбцами), которые нам необходимо учитывать. Некоторые модели, такие как Наи́вный ба́йесовский классифика́торએ, используют допущение об отсутствии корреляции между отдельными характеристиками, поэтому этот шаг имеет решающее значение.
Итак, давайте построим диаграммы рассеяния для различных комбинаций предметов.
sns.set_style('darkgrid')
plt.title('Зависимость между оценками по математике и чтению',size=16)
plt.xlabel('Оценка по математике',size=12)
plt.ylabel('Оценка по чтению',size=12)
sns.scatterplot(x='math_score', y='reading_score', data=data, hue='gender', edgecolor='black', palette='cubehelix', hue_order=['male','female'])
plt.show()

plt.title('Зависимость между оценками по математике и письму',size=16)
plt.xlabel('Оценка по математике',size=12)
plt.ylabel('Оценка по письму',size=12)
sns.scatterplot(x='math_score', y='writing_score', data=data, hue='gender', s=90, edgecolor='black', palette='cubehelix', hue_order=['male','female'])
plt.show()

sns.set_style('whitegrid')
plt.title('Зависимость между оценками по чтению и письму',size=16)
plt.xlabel('Оценка по чтению',size=12)
plt.ylabel('Оценка по письму',size=12)
sns.scatterplot(x='reading_score', y='writing_score', data=data, hue='gender', s=90, edgecolor='black', palette='colorblind',hue_order=['male','female'])
plt.show()

Итак, диаграмма рассеянияએ предполагает высокую степень корреляции между оценками учащихся по разным предметам. Оценки учащихся по математике и (чтению, письму) мало разбросаны, но, как правило, они показывают рост, поэтому, если ученик набирает больше по математике, то он или она также обычно набирает больше по другим предметам. С другой стороны, зависимость оценок по чтению и письму более сгруппирована вдоль прямой линии.
Подобный анализ многое говорит нам о важности EDA, ведь если бы не EDA на получение такого результата ушли бы часы.
Мы знаем, что «интегральная оценка» — это обобщенный показатель, рассчитанный на основе значений измерений и характеризующий конкретный набор данных. Поэтому, с технической точки зрения, она всегда вызывает особый интерес: какое из измерений больше всего влияет на её значение.
Чтобы это выяснить, построим еще один график, :
total_marks = ((data['math_score'] + data['reading_score'] + data['writing_score'])/300)*100
data['Интегральная оценка'] = total_marks
kde_data = data[ ['math_score','reading_score','writing_score','Интегральная оценка'] ]
sns.set_style("darkgrid")
sns.kdeplot(data=kde_data,shade=True, palette='colorblind')
plt.show()
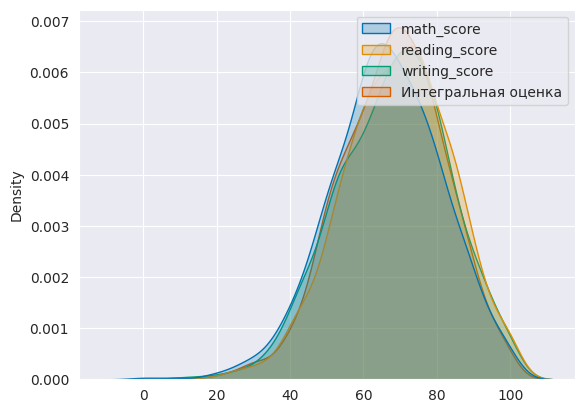
Совершенно очевидно, что почти все предметы в одинаковой степени влияют на общий балл. Таким образом, нам не нужно рассматривать какую-либо конкретную функцию, влияющую на Интегральную оценку больше, чем другие.














Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ


