
Россия, Омск


СДЕЛАЙТЕ СВОИ УРОКИ ЕЩЁ ЭФФЕКТИВНЕЕ, А ЖИЗНЬ СВОБОДНЕЕ
Благодаря готовым учебным материалам для работы в классе и дистанционно
Скидки до 50 % на комплекты
только до
Готовые ключевые этапы урока всегда будут у вас под рукой
Организационный момент
Проверка знаний
Объяснение материала
Закрепление изученного
Итоги урока

Была в сети 21.04.2024 12:34

Брух Таисия Викторовна
Учитель информатики
42 года
Местоположение
Специализация
«Кодирование текстовой информации»
Категория:
Информатика
04.11.2021 08:59
Учебник:
Информатика ООО «БИНОМ. Лаборатория знаний» Поляков К.Ю., Еремин Е.А. 8 класс 2018. - 256 с.

Цели и задачи урока:
— познакомиться со способами кодирования и декодирования текстовой информации с помощью кодовых таблиц и компьютера;
— познакомиться со способом определения информационного объема текстового сообщения;
— познакомиться с алгоритмом Хаффмана.
Ход урока:
1. Организационный момент
2. Проверка домашнего задания (перевод СС)
3. Самостоятельная работа по СС
(смотри приложение)
4. Изучение нового материала
Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Формула Хартли определяет количество информации в зависимости от количества возможных вариантов:
N=2i, где
N — это количество вариантов,
i — это количество бит, не обходимых для кодирования.
Если же мы преобразуем эту формулу и примем за N — количество символов в используемом алфавите (назовем это мощностью алфавита), то мы поймем, сколько памяти потребуется для кодирования одного символа.
N=2i, где N — кол-во возможных вариантов
i — кол-во бит, потребуемых для кодирования
Итак, если в нашем алфавите будет присутствовать только 32 символа, то каждый из них займет только 5 бит.

И тогда каждому символу мы дадим уникальный двоичный код. Такую таблицу мы будем назвать кодировочной.


Первая широко используемая кодировочная таблица была создана в США и называлась ASCII, что в переводе означало American standard code for information interchange. Как вы видите, в таблице присутствуют не только латинские буквы, но и цифры, и даже действия. Каждому символу отводится 7 бит, а значит, всего было закодировано 128 символов.

Но так как этого количества было недостаточно, стали создаваться другие таблицы, в которых можно было закодировать и другие символы. Например, таблица Windows-1251, которая, по сути, являлась изменением таблицы ASCII, в которую добавили буквы кириллицы. Таких таблиц было создано множество: MS-DOS, КОИ-8, ISO, Mac и другие:

Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:

Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков. На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст. Поэтому существуют различные алгоритмы неравномерной кодировки текста, например, алгоритм Хаффмана.

АЛГОРИТМ ХАФФМАНА
Идея алгоритма Хаффмана основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
Пусть нам дано сообщение aaabcbeeffaabfffedbac.
Чтобы узнать наиболее выгодный префиксный код для такого сообщения, надо узнать частоту появления каждого символа в сообщении.
Шаг 1.
Подсчитайте и внесите в таблицу частоту появления каждого символа в сообщении:

У вас должно получиться:

Шаг 2.
Расположите буквы в порядке возрастания их частоты.

Шаг 3.
Теперь возьмем два символа с наименьшей чистотой и представим их листьями в дереве, частота которого будет равна сумме частот этих листьев.
Символы d и c превращаются в ветку дерева:

Шаг 4.
Проделываем эти шаги до тех пор, пока не получится дерево, содержащее все символы.
Итак, сортируем таблицу:

Шаг 5.
Объединяем символ e и символ cd в ветку дерева:
d
C

Шаг 6.
Сортируем:

Шаг 7.

Шаг 8.
Сортируем:

Шаг 9.


Шаг 10.
Сортируем:
Шаг 11.

Шаг 12.
Получился префиксный код. Теперь осталось расставить 1 и 0. Пусть каждая правая ветвь обозначает 1, а левая — 0.

Шаг 13.
Составляем код буквы, идя по ветке дерева от буквы к основанию дерева.
Тогда код для каждой буквы будет:


Задание №1
Закодируйте ASCII кодом слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
|
M |
O |
S |
C |
O |
W |
|
1001101 |
1001111 |
1010011 |
1000011 |
1001111 |
1110111 |
ОТВЕТ: 100110110011111010011100001110011111110111
Задание №2
Используя табличный код Windows1251, закодируйте слово КОМПЬЮТЕР.
Решение:
|
К |
О |
М |
П |
Ь |
Ю |
Т |
Е |
Р |
|
234 |
206 |
204 |
239 |
252 |
254 |
242 |
197 |
208 |
Ответ: 234206204239252254242197208
Задание №3
Используя алгоритма Хаффмана, закодируйте сообщение: Россия
Решение:


|
|||
|



Давайте все левые ветви обозначим «1», а правые – «0»

Таким образом: С — 0, Р — 101, О — 100, И — 111, Я — 110
ОТВЕТ: 10110000111110
Просмотр содержимого документа
««Кодирование текстовой информации»»
9 урок, 8 класс
Учитель: Брух Т.В.
Дата: __________
Тема: «Кодирование текстовой информации»
Цели и задачи урока:
— познакомиться со способами кодирования и декодирования текстовой информации с помощью кодовых таблиц и компьютера;
— познакомиться со способом определения информационного объема текстового сообщения;
— познакомиться с алгоритмом Хаффмана.
Ход урока:
1. Организационный момент
2. Проверка домашнего задания (перевод СС)
3. Самостоятельная работа по СС
(смотри приложение)
4. Изучение нового материала
Вся информация в компьютере хранится в двоичном коде. Поэтому надо научиться преобразовывать символы в двоичный код.
Формула Хартли определяет количество информации в зависимости от количества возможных вариантов:
N=2i, где
N — это количество вариантов,
i — это количество бит, не обходимых для кодирования.
Если же мы преобразуем эту формулу и примем за N — количество символов в используемом алфавите (назовем это мощностью алфавита), то мы поймем, сколько памяти потребуется для кодирования одного символа.
N=2i, где N — кол-во возможных вариантов
i — кол-во бит, потребуемых для кодирования
Итак, если в нашем алфавите будет присутствовать только 32 символа, то каждый из них займет только 5 бит.
![]()
И тогда каждому символу мы дадим уникальный двоичный код. Такую таблицу мы будем назвать кодировочной.
![]()
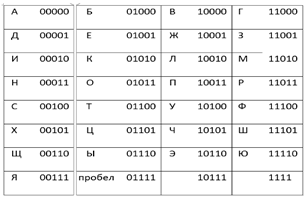
Первая широко используемая кодировочная таблица была создана в США и называлась ASCII, что в переводе означало American standard code for information interchange. Как вы видите, в таблице присутствуют не только латинские буквы, но и цифры, и даже действия. Каждому символу отводится 7 бит, а значит, всего было закодировано 128 символов.
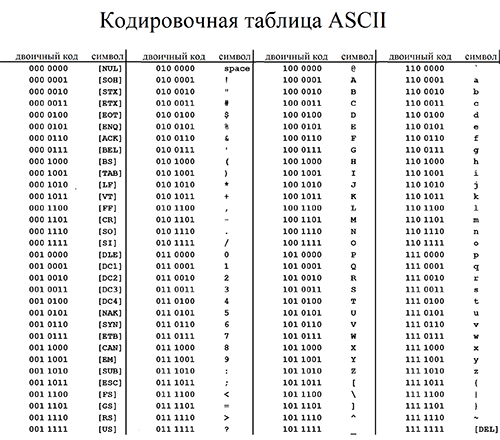
Но так как этого количества было недостаточно, стали создаваться другие таблицы, в которых можно было закодировать и другие символы. Например, таблица Windows-1251, которая, по сути, являлась изменением таблицы ASCII, в которую добавили буквы кириллицы. Таких таблиц было создано множество: MS-DOS, КОИ-8, ISO, Mac и другие:
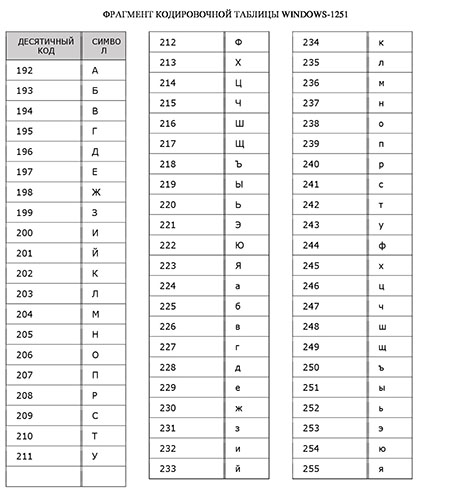
Проблема использования таких различных таблиц приводила к тому, что текст, написанный на одном компьютере, мог некорректно читаться на другом. Например:
Поэтому была разработана международная таблица кодировки Unicode, включающая в себя как символы английского, русского, немецкого, арабского и других языков. На каждый символ в такой таблице отводится 16 бит, то есть она позволяет кодировать 65536 символов. Однако использование такой таблицы сильно «утяжеляет» текст. Поэтому существуют различные алгоритмы неравномерной кодировки текста, например, алгоритм Хаффмана.
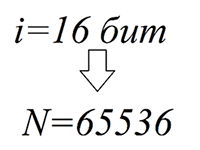
АЛГОРИТМ ХАФФМАНА
Идея алгоритма Хаффмана основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
Пусть нам дано сообщение aaabcbeeffaabfffedbac.
Чтобы узнать наиболее выгодный префиксный код для такого сообщения, надо узнать частоту появления каждого символа в сообщении.
Шаг 1.
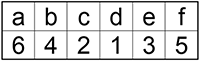
Подсчитайте и внесите в таблицу частоту появления каждого символа в сообщении:
![]()
У вас должно получиться:
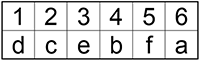
Шаг 2.
Расположите буквы в порядке возрастания их частоты.
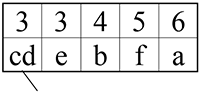
Шаг 3.
Теперь возьмем два символа с наименьшей чистотой и представим их листьями в дереве, частота которого будет равна сумме частот этих листьев.
Символы d и c превращаются в ветку дерева:
Шаг 4.
Проделываем эти шаги до тех пор, пока не получится дерево, содержащее все символы.
Итак, сортируем таблицу:
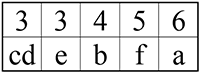
Шаг 5.
Объединяем символ e и символ cd в ветку дерева:
d
C
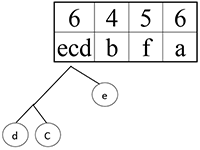
Шаг 6.
Сортируем:
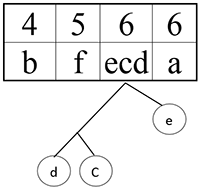
Шаг 7.
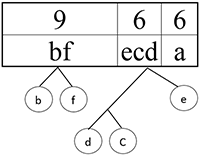
Шаг 8.
Сортируем:
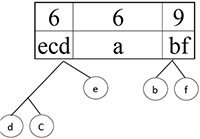
Шаг 9.
Шаг 10.
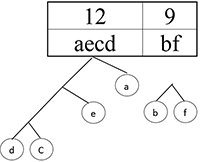
Сортируем:
Шаг 11.
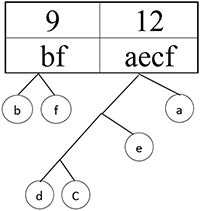
Шаг 12.
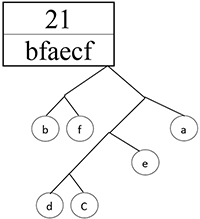
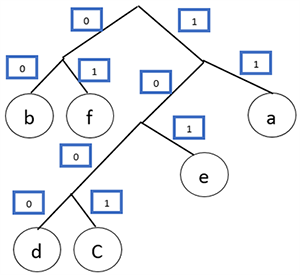
Получился префиксный код. Теперь осталось расставить 1 и 0. Пусть каждая правая ветвь обозначает 1, а левая — 0.
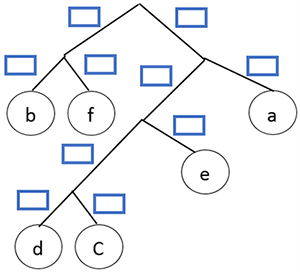
Шаг 13.
Составляем код буквы, идя по ветке дерева от буквы к основанию дерева.
|
|
|
|
Тогда код для каждой буквы будет:
![]()
Задание №1
Закодируйте ASCII кодом слово MOSCOW.
Решение:
Составим таблицу и поместим туда слово MOSCOW. Используя таблицу ASCII кодов, закодируем все буквы слова:
| M | O | S | C | O | W |
| 1001101 | 1001111 | 1010011 | 1000011 | 1001111 | 1110111 |
ОТВЕТ: 100110110011111010011100001110011111110111
Задание №2
Используя табличный код Windows1251, закодируйте слово КОМПЬЮТЕР.
Решение:
| К | О | М | П | Ь | Ю | Т | Е | Р |
| 234 | 206 | 204 | 239 | 252 | 254 | 242 | 197 | 208 |
Ответ: 234206204239252254242197208
Задание №3
Используя алгоритма Хаффмана, закодируйте сообщение: Россия
Решение:
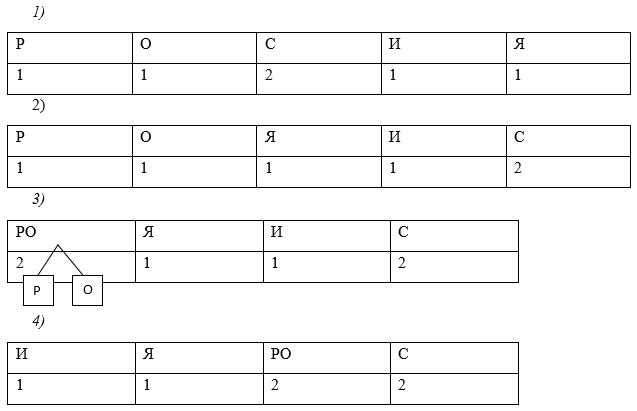
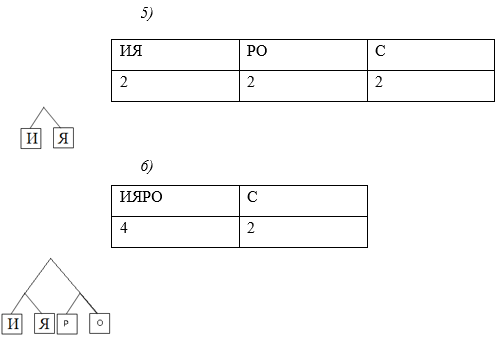
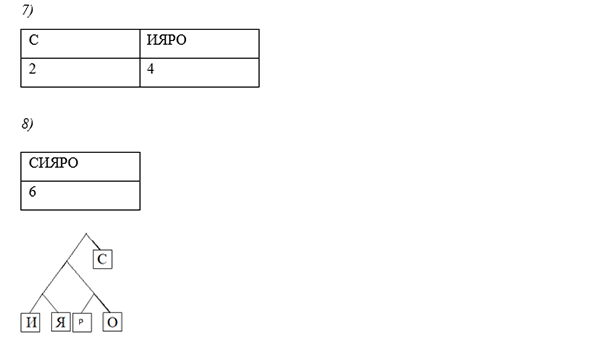
![]()
Давайте все левые ветви обозначим «1», а правые – «0»
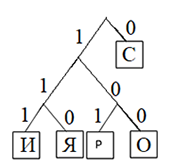
Таким образом: С — 0, Р — 101, О — 100, И — 111, Я — 110
ОТВЕТ: 10110000111110














Вебинар для учителей

Свидетельство об участии БЕСПЛАТНО!
Полезное для учителя

Реализация образовательных программ осуществляется с применением исключительно электронного обучения и ДОТ


